
Lessons from Building ActSolo.AI - An AI Teleprompter and Scene Partner for My Wife
TL;DR
ActSolo.AI started as a simple browser teleprompter for my wife, but browser speech limitations forced major architectural pivots and deeper engineering than expected.
Moved to OpenAI Realtime API and ultimately an ElevenLabs Agent unlocked reliable VAD, turn-taking, and a unified Conversation Engine with ElevenLabs Agent that cut complexity and stabilized the experience.
The biggest lesson: abstraction wins—building a provider-agnostic engine and embracing early refactors created a future-proof foundation that finally made the product behave like a real scene partner.
The Journey Starts (July 2025) - Phase One: the browser
131 messages sent, 73 AI edits, and some extra ‘credits’ later, I’ve reached the end of a 2-week sprint in my first project with Lovable.
The inspiration started at home: My wife, an actor, needed a better way to rehearse and record lines for auditions without depending on my availability as her “scene partner.” With two young kids, it’s nearly impossible to narrow down quiet time with both of us to record scenes without some extra help.
We had settled on creating separate recordings for a while, combining them in post, but it never felt very natural. That’s what inspired me to try building a teleprompter web-based solution.
So I set out to build: ActSolo.AI.
ActSolo.AI is aweb-based AI teleprompter where actors will be able to copy/paste scripts, assign AI voices (from ElevenLabs) that would actively read their ‘scenes’ with them with emotive control. Yes, AI is coming even for scene readers.
I started planning:
Wrote a product requirements doc (PRD – outlines requirements, costs, features, etc.)
Defined risks: voice tech, script logic, session reliability, devices, legal stuff
Built a work breakdown structure (WBS – breakdown of project scope)
Uploaded all of my specific details to ChatGPT as my co-developer since I already had a subscription plan and then to Lovable. The product was coming together
Tech stack:
Lovable
Supabase for backend logs and data
Integrated with ElevenLabs API for the high quality of their voices and for the Text-to-Speech capabilities
Here is a screenshot of the rehearsal page with the voices from ElevenLabs scroll open in order to view and select a variety of different voices to rehearse from. Actors can actively edit their scrip while rehearsing, view the screen in full, zoom in/out, control speeds, and assign lines for the AI to read by bolding or using italics.
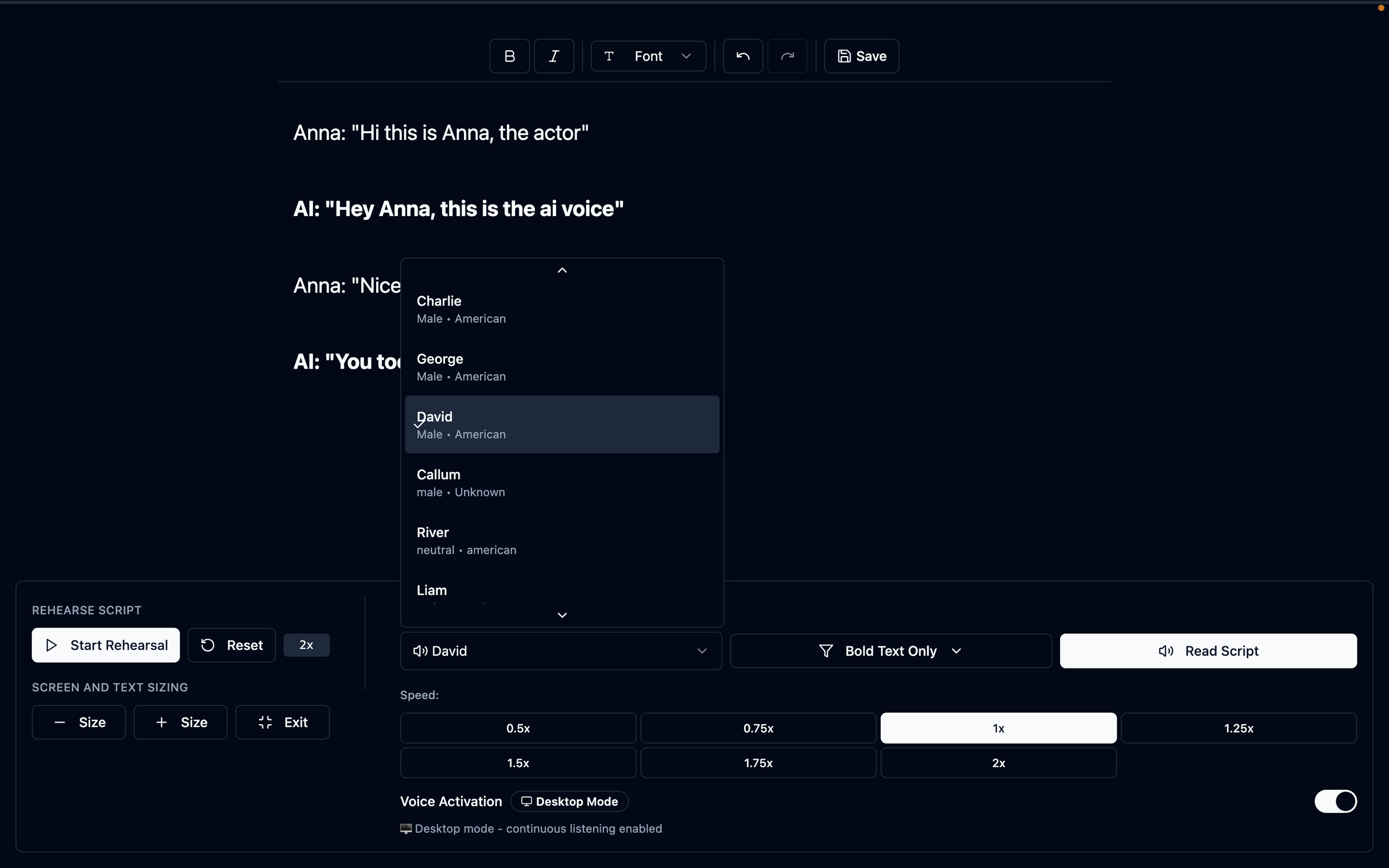
Supabase handled everything well and it’s been amazing to review the logs when troubleshooting. The backend was almost never the source of my biggest problems.
Instead, I realized most recently, it’s the browser’s native Web Speech limitations, across Safari, Chrome, and Firefox.
Throughout the project, I would make little strides here and there, feeling waves of happiness, then run into errors, where the app wasn’t listening like I needed it to, or it wouldn’t read the script text.
Unexpectedly, I spent about 90% of the time:
Reviewing code
Setting log creation and reviewing logs
Debugging filters
Trying to realize why the AI wouldn’t stop speaking. Why it did start speaking…
Testing into browser dev tools
At times I was pulling my hair out…but it’s been an awesome experience to build and own the product with these ‘vibe-coding’ tools.
I spent a week refactoring, building smarter state machines to make the rehearsal flow more predictable, maintainable, and extensible while reducing bugs, but I should’ve done this sooner.
I chased edge cases and learned a lot with ChatGPT as my co-developer, note taker, and prompt refiner.
So, nothing on the backend, no major issues with ElevenLabs—just browser quirks and limitations that I didn’t realize until recently, which finally made me realize that I'm going to need to change things up.
Key lessons:
Just build it, and test: I still saved time, money, sanity, and learned a bunch building with Lovable. I can't wait to try building something new
Of course, put the user first: If native tools don’t cut it, it’s smarter to pivot
Platform limits: No amount of clever prompting and code with client-side solutions will make browser voice limitations work like I want (yet). This project will need server-side processing to handle heavy lifting.
Logs are a real resource: I was able to find where the issues really were
Chat management: At first, I likely burned through credits too quickly but then I became more strict and found a good prompt rhythm with GPT before going back to Lovable with changes.
Phase Two: Integrating OpenAI Realtime API
After my first sprint, I thought I’d need to build a full cloud-based stack to enable real-time voice interaction in ActSolo.AI.
Then, while researching another project, I came across OpenAI’s Realtime API + Voice Activity Detection (VAD) - and it clicked.
Now, instead of spinning up a whole new part of this project, I’m actively working on updating the ActSolo teleprompter to support speech-to-speech (S2S) in its current state.
With the ability to keep the mic open, the OpenAI addition will enable:
- Cue-word detection
- Detection when the user has started or stopped speaking
- Turn-taking based on end-of-speech so the AI voices from ElevenLabs respond naturally when an actor finishes their line
At this stage, this project has become complex. It started to need some real engineering so I began using VS Code with Lovable to fully support the build.
I’m sure this is old news for developers but…VS Code has been awesome for a first-time user:
- I upload my .md project plans so I can always reference them with Lovable
- I ask questions and debug in context, using Agent + Chat modes
- Every edit is tracked - I can test, debug, and more easily see the full project components
- Most importantly, it cuts down on Lovable credits by reducing chat volume
Recently, I was happy to have successfully debugged and connected the OpenAI API locally through the Terminal after Lovable was having errors figuring it out.
With the help of a custom GPT, I figured out how to:
- Run Supabase CLI commands
- Set and update secrets
- Deploy edge functions
- Customize logs and test error flows in real time
Now, I’m not a developer, but for every new project, I’m going to utilize VSC with Lovable and would recommend for anyone starting out with it to also include it in their workflow.
Phase Three (December 2025): Successfully adding a unified Conversation Engine and ElevenLabs Agent
After wrestling with the hybrid OpenAI + ElevenLabs setup, I developed a more durable long-term approach: a provider-agnostic Conversation Engine that is the new core software for ActSolo.AI’s real-time flow.
The previous “engine” behavior was spread across hooks, Supabase functions, and state machine callbacks and there was no clear place to swap providers or let Eleven handle turn-taking. I kept running into events that were “intentionally dropped” so to keep the initial OpenAI relay from failing and losing the ability to forward cues and hand-offs cleanly, a refractor with a ConversationEngine abstraction *should* solve the core problems.
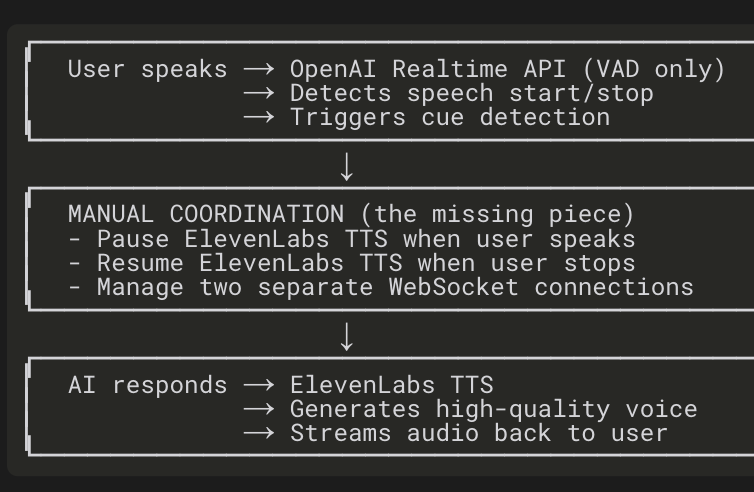
It looked like this:
Previous Issues:
Two separate systems to coordinate
Manual pause/resume logic needed
Potential timing issues between systems
More complex state management
Higher latency from system switching
One new element was the addition of an ElevenLabs Agent. The Conversational AI now required an Agent and made this refractor work. It completely changed the app architecture.
It’s cool. Agents are configured with a system prompt defining personality + speaking behavior and conversation settings (turn-taking eagerness, VAD sensitivity, interruption rules). This was all stuff that I was manually trying to stitch together across OpenAI and ElevenLabs and it just became too complex.
So, instead of using ElevenLabs as “just a Text-to-Speech (TTS) engine,” I’m now also leaning on the Realtime API instead of using OpenAI’s. This moved it into the “AI scene partner” territory for a working MVP.
Here’s the new flow:

What this new approach solves
By implementing a Conversation Engine and backing it with an ElevenLabs Agent, ActSolo.AI now has:
A single websocket that handles mic input, VAD, turn-taking, agent reasoning, and TTS
A predictable agent “reader” persona that stays consistent for users
A clean separation between:
Domain logic (cues, scenes, character assignments)
UI logic (RehearsalMode, script editor)
Provider logic inside the engine
A future-proofed architecture that lets me swap providers or engines without touching UI code
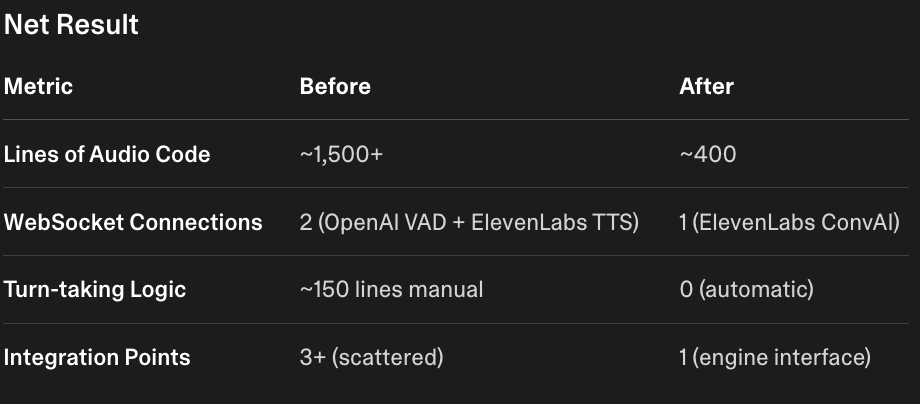
~25% reduction of code
From 5 coordination points -> 1 engine
From 3 WebSocket connections -> 1 connection
Turn-taking and built-in VAD: Manual -> Automatic from ElevenLabs
What’s great about this update is that I’m already using the ElevenLabs API, but will utilize a different call for the Conversational AI endpoint.
Phase 3 Learnings:
You need “one brain” for the conversation, not two hacks glued together. Adding an ElevenLabs Agent gave me a cohesive conversational core - something my hybrid setup tried to approximate through manual effort. The Agent concept merges reasoning + TTS + VAD under one identity. It’s already cleaner and more predictable.
Abstraction buys long-term flexibility. Introducing a Conversation Engine means I’m no longer threading vendor-specific events. New features will be able to ship faster because I’m building stable, domain-level events.
Early refactor pain saves months of future debugging. The hybrid approach worked, but barely. Timing bugs, race conditions, double-speech, and state mismatches were eating 60% of my dev time. This one abstraction layer eliminated tons of bugs and complexity.
What’s Next
This has finally come together for a reliable, actor-friendly, rehearsal experience! ActSolo.AI will eventually be a product offering under my wife’s business, Cameraon Creative.
If you’re reading this and have any feedback, please reach out!